Back to all news
What is Data Mesh and why do I care?
In recent years the Data Mesh concept has revolutionized how organizations work with their data. It enabled businesses to produce data reports with unparalleled speed and agility. The value of almost any company is based on 2 aspects - its data and people (staff, partners, customers). And people need the right data at the right time to make the right decisions.
The known theory defines that data could create information, information could create knowledge, and knowledge must be a part of wisdom. Just synergy of data could bring information for decision making. And, making the right decisions based on data means grabbing a value from data. There have been multitudes of solutions proposed to address this fundamental organizational hunger for getting the data quickly. This ranged from traditional Oracle-powered DWH, through Hadoop, Azure Synapse to cloud-native highly parallel databases such as Snowflake or Google BigQuery.

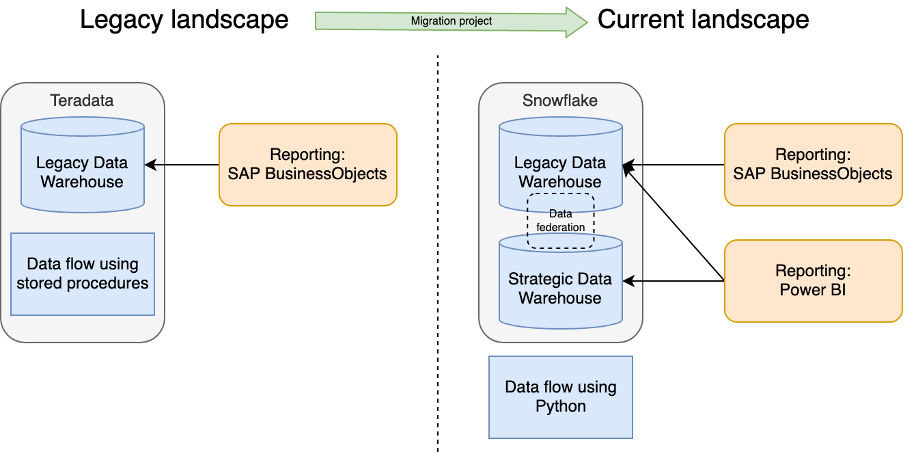
All of these tools and approaches failed to address the major shortcoming – data centralization. There is always a more or less centralized team governing or even creating, the data platform. This central element results in expensive data solutions and takes too long to deliver the required data to business users. Sometimes even the business needs passed and the report was not needed anymore. Data Mesh is a set of design and architecture principles created to enable data democratization without such a bottleneck. Data Mesh is not a product that can be bought and magically solve all the problems. Instead, it needs to be taken as a set of guidelines to be tuned to fit a particular organization or project.
Data Mesh principles also affect target data stack selection – some products enable the rapid roll-out of Data Mesh architecture more easily than others. But there also isn’t one-size-fits-all, so when designing interim and target data stacks, we always consider existing products and tools, organizational data maturity level, available resources, budgets, current pain points, and fit for a long-term vision. When applied pragmatically and customized to the organization, Data Mesh acts as a “10x” factor for increased speed and agility in data deliveries.
Data Mesh: it’s not rocket science… or is it?
We like to use the analogy between traditional approaches such as DWH or ODS and modern Data Mesh to the difference between Space Shuttle and SpaceX rockets. Space Shuttle was an enormously expensive program because every component had to work flawlessly the very first time. And every component had to work flawlessly the first time because it was such an expensive program that failure was not economically or politically possible. SpaceX uses a very much different approach. Failure is not just accepted as an option, it is sometimes a desired outcome to gather most of the data. Their rocket designs and builds are iterating very quickly, and there is constant learning feedback.

The catch is that the SpaceX approach was impossible 20 years ago. Many technologies were not mature enough or simply not existing at all – from computer designs, friction welding, and new metallurgy materials down to 3D printers and many others. They enable SpaceX to iterate extremely quickly with low risk and costs.
A similar situation is with Data Mesh principles. Whilst they are technology-agnostic, they require for efficient implementation certain technical capabilities and maturity – such as a highly flexible reporting/visualization system, data transfer and transformation engine (ELT) supporting distributed teams, and automated CI/CD pipelines and security layer enabling quick and trusted user access control, sensitive data masking/randomization etc. Data mesh should cover all these domains.
History rhymes with itself
The Data Mesh movement resembles an evolution in online integration. In the past, an SOA model leveraging the ESB layer that acted as a central place to expose organization-wide APIs often used a canonical service data model. There were created many WebService standards from security and service discoverability to distributed transactions. This approach worked great technically, but such a middleware team quickly became a bottleneck as it had to play a delivery-critical role in practically any project.
Over time this approach evolved into a microservice, REST-based approach based rather on conventions and without any centralized component. Focus shifted from centrally designed and governed services to solutions favoring speed of delivery, the ability for teams to efficiently expose and consume services as needed in the context of their mission delivery. Such an approach may not look pretty on architecture diagrams where the central ESB component is replaced with “spaghetti integration”, but which one actually better represents real-world complexity?

A similar shift happened on the security layer – rather than checking and enforcing security on the ESB layer JWT/OAuth approach decoupling authentication (determining identity and assigned roles) with actual authorization and security roles being always evaluated in the business context of the service provider. The ease of exposing and consuming a microservice led to the creation of a vibrant service marketplace where REST API is now expected to be part of any new solution. It also erased the difference between “UI integration” and “system-to-system integration”. Frontends are now consuming the very same REST API as any other system. This simplified development and maintenance as developers nowadays don’t have to think about and support two different integration and security models.
We often hear concerns from current ODS/DWH developers that the Data Mesh approach will obsolete their role. In fact, the opposite is true. Their role will evolve into being more tightly coupled with actual business users and Data Product consumers, who will be critical in building complex Data Products. It will become a more rewarding role as they will be able to directly see the results of their work being used and receive feedback firsthand. Data Mesh methodology will enable them to quickly incorporate requested changes without waiting for months-long frustrating release cycles.
Data Mesh principles
The core of Data Mesh are these 3 principles. They aim to enable anybody to safely create, share and consume Data Products as they choose fit. There is no centralized team that can be a bottleneck instead, it is replaced by centralized governance enforcing security, compliance, performance and data privacy rules.
1. Build Data Products
The basic building block of Data Mesh is a Data Product. It is created to provide data for a specific user’s needs. It consists of at least one dataset from one or more data sources. It can possibly consist of other Data Product(s). They can be roughly classified into 2 categories:
- Source-aligned DPs – these are provided directly by a source system(s). For example Customer, Address, Account, Order, etc. They can consist of a logical join of datasets from multiple source systems.
- Composite (or consumer-aligned) DPs – these Data Products are built using dataset(s) from another DP(s) and possibly other data sources. They provide additional business value through data enrichment, cleaning, or aggregation. Examples are e.g. Customers with active Accounts, Customer LTV, frequently bought together Articles, etc.
The most important aspect of Data Product is that anybody in the organization can define and publish a new DP.
2. Publish and share Data Products
The main differentiator in Data Mesh compared to previous approaches is in true de-centralization and democratization of users’ access to data. Access to the dataset of a Data product can be provided by multiple methods (REST API, SQL, batch file, etc.). The underlying technology data stack must enable users to quickly and independently create new Data Product and then publish it into a Data Product Catalog to share it with a wider audience. Tools must also support the efficient creation of new, composite, Data Products where a user will “plug-in” existing Data Product(s), additional source systems and/or external data, write necessary transformation login (in whatever user SQL, Python, R, Java, etc.) and store resulting datasets for further access (e.g. in a DB, as a batch file or even as a streaming set of messages/events).
To share a Data Product user must also provide additional metadata about it – such as plain text description, schema(s), performance limitations, operational metrics (refresh rates), data security classification, and others.
3. Manage security access
It is obvious that sharing sensitive data must be done in a controlled and secure manner. This means that there must exist a mechanism to define on Data Product level required access rules on the entity, attribute (column), and record (row) levels. These controls can specify more fine-grained than a typical allow/deny rule – it can allow attributes to be masked, randomized, or pseudo-randomized (e.g. preserving age in randomized day of birth).
Whilst it is possible to configure these controls and rules individually on each source system and also throughout various data products, this approach easily leads to the exponential growth of complex rules (GRANTs, etc.) and is practically unmanageable and unauditable. Instead, it is highly desired to have a centralized tool that will enforce security governance rules end-to-end – from source systems through interim data products to the reports themselves. Only then is it possible to ensure various regulatory compliance requirements for GDPR, PCI-DSS, HIPAA, and others – such as separation of duties, data masking/pseudonymization, PII & PAN data storage controls, encryptions at-rest & at-transit, etc.
These controls are based on traditional RBAC (role-based) or more modern ABAC (attribute-based) approaches, but they must be centralized, owned, and managed by data providers. Without strong and trusted Security and Governance Guardrails and tooling enabling it will, any Data Mesh concept fail to deliver the expected business benefits.
Link to Article #2 of our Data Mesh series: What is Data Mesh and why do I care? – Part II.
Author
 Miloš Molnár
Miloš Molnár
Grow2FIT BigData Consultant
Miloš has more than ten years of experience designing and implementing BigData solutions in both cloud and on-premise environments. He focuses on distributed systems, data processing and data science using Hadoop tech-stack and in the cloud (AWS, Azure). Together with the team, Miloš delivered many batch and streaming data processing applications.
He is experienced in providing solutions for enterprise clients and start-ups. He follows transparent architecture principles, as well as cost-effective and sustainable within a specific client’s environment. It is aligned with enterprise strategy and related business architecture.
The entire Grow2FIT consulting team: Our team
Related services


 Kamil Madáč
Kamil Madáč

 Kamil Madáč
Kamil Madáč